How Words Shape Machines
Exploring how language models work, where they fall short, and why phrases like "carbon pricing" v "carbon tax", "illegal immigrant" v "undocumented immigrant" can subtly steer responses.

Introduction
Language models don’t just answer questions; they answer them in the reason language we input. In this post, I will attempt to reason how modern AI systems actually generate text, why they match patterns as opposed to think independently, and what kinds of built‑in constraints and blind spots they carry with them. From there, I aim to look at how seemingly small linguistic choices: “global warming” versus “climate change,” “war in Iran” versus “attack on Iran,” “illegal immigrant” versus “undocumented immigrant”, shift not only public perception but also the kinds of answers an AI is likely to produce. The goal is to show that wording is never neutral but actively imbued with unique subtleties: the diction we choose quietly steers both machines and readers toward particular frames, values, and conclusions. No two words are the same.
To understand how diction, or choice of words, actually shapes the response we get from generative AI models, a basic understanding of the model’s thought process is required.
How AI Thinks
Artificial intelligence responds the way it does because it has learned statistical patterns in language, and because small choices in wording strongly steer those patterns and how humans interpret them. When you type a question, the system first breaks your text into tokens, which are word pieces like “climate” or “immigrant.” These tokens are mapped to vectors and passed through many transformer layers that model relationships among tokens via self‑attention.
The main building block is the transformer layer, which uses self‑attention to decide which parts of the input matter most for each token. Each token is projected into three vectors: a query (what this position is “looking for”), a key (how this position presents itself to others), and a value (the information it can contribute).
Because the model has seen countless examples of explanations, proofs, stories, and arguments, it can reproduce similar multi‑step structures when prompted. And when you ask it to “show reasoning,” you are essentially telling it to sample from parts of its distribution where humans wrote reasoning chains, so it generates tokens that look like steps in an argument or calculation.
Constraints and Limitations
Because of how AI models are built, certain limitations or errors are almost guaranteed. AI models don’t understand but are approximating likely continuations based on training data patterns, this leads to fluent but factually incorrect statements, also known as hallucinations. They also inherit and often amplify biases in their training data, including cultural, political, and linguistic biases. This factor is augmented by a company’s and country’s political interests. This is why many AI models require specific prompting to uncover both sides of a story, or provide a historically accurate account of an event. For example, Deepseek won’t talk about Taiwan, Tiananmen Square or anti-Chinese discourse more broadly. It’s also important to understand the perspective from which AI creates narratives and posits solutions to issues. For, this is something that is not explicitly conveyed when you ask a model to show its reasoning, but evidently undergirds its core assumptions. As a logical consequence, AI models struggle to show transparent reasoning, making it hard to inspect why or how a particular answer was shown. These constraints are then overlaid with explicit guardrails (content policies, style instructions) that further shape diction, topics, and stance.
How Style Shapes Responses
Because models are trained on human text, they absorb linguistic norms about tone, politeness, hedging, and framing, among other things. Regarding tone, inputs written in formal academic style tend to elicit formal output — formal prompts for an English or History essay in school are good examples. Casual slang tends to elicit more informal responses, as the model mirrors patterns associated with that style in its data.
Tone: Inputs written in formal academic style tend to elicit formal output; casual slang tends to elicit more informal responses, as the model mirrors patterns associated with that style in its data.
Dialect: Models trained predominantly on mainstream American English often misinterpret or “correct” non‑standard dialects, shaping both what they understand and how they reply.
Pragmatics: The model picks up on cues like politeness markers, hedges (“maybe,” “I guess”), and direct imperatives (“list,” “explain in detail”), which steer both structure and stance (e.g., cautious vs confident).
Discourse structure: Question forms (“why,” “how,” “compare”) and connectives (“however,” “on the other hand”) push the model toward explanations, contrasts, lists, and other specific discourse moves.
Framing Choices — How Diction Affects Outputs
Every word is charged. For example, something every child experiences is their parents telling them: “Don’t say ‘hate’, that’s a strong word.”, and the child subsequently saying: “I dislike [something].”
Communication research shows that labels like “global warming” and “climate change” are not neutral synonyms; they activate different associations and responses in humans, especially among people who are less politically anchored.
Studies find that “global warming” tends to evoke more concrete, heat‑related imagery and can sometimes heighten concern or emotional response, particularly among disengaged or politically independent audiences.
“Climate change” can sound more abstract or technical; in some contexts it reduces emotive polarization but may also feel less urgent to some audiences.
A language model trained on such data learns that “global warming” frequently co‑occurs with certain narratives (e.g., partisan debate, severe heat) while “climate change” appears in others (e.g., IPCC reports, adaptation policy), so its answers will subtly differ depending on the term you choose. This means that the selection of sources upon which the AI bases its response vary with diction.
The difference in outputs isn’t a unique symptom of AI but rather says a lot more about how the media portrays events.
Now, if we take something more polarizing than “climate change” v “global warming”, such as “war in Iran” v “attack on Iran”, the results differ to a much greater extent. Here, word choice similarly frames agency, duration, and moral valence in conflict language.
“The United States’s war in Iran” suggests a prolonged, symmetric conflict, with institutionalized military engagement and an ongoing campaign.
“The United States’s attack on Iran” frames a discrete action, highlights the aggressor, and foregrounds a specific event rather than a continuous state of war.
Because the model has seen enormous amounts of news and political discourse, it has learned correlations between terms like “war,” “intervention,” “strike,” “attack,” or “operation” and particular argumentative patterns (justification, condemnation, legal framing, humanitarian framing). Given “war in Iran,” the model will be more likely to continue with language about strategy, duration, and campaigns; given “attack on Iran,” it will more likely discuss legality, proportionality, or immediate casualties, mirroring those patterns. This is why even small shifts in wording can change both:
What the model thinks you are asking for: descriptive history vs moral evaluation vs legal analysis.
Which parts of its learned distribution become more probable: technical policy talk vs rights‑based condemnation vs neutral/informative reporting style.
But circling back to the idea that this is an intentional “flaw” of the media, upon a google search of “war in Iran” v “attack on Iran”, the difference in news sources is evident.
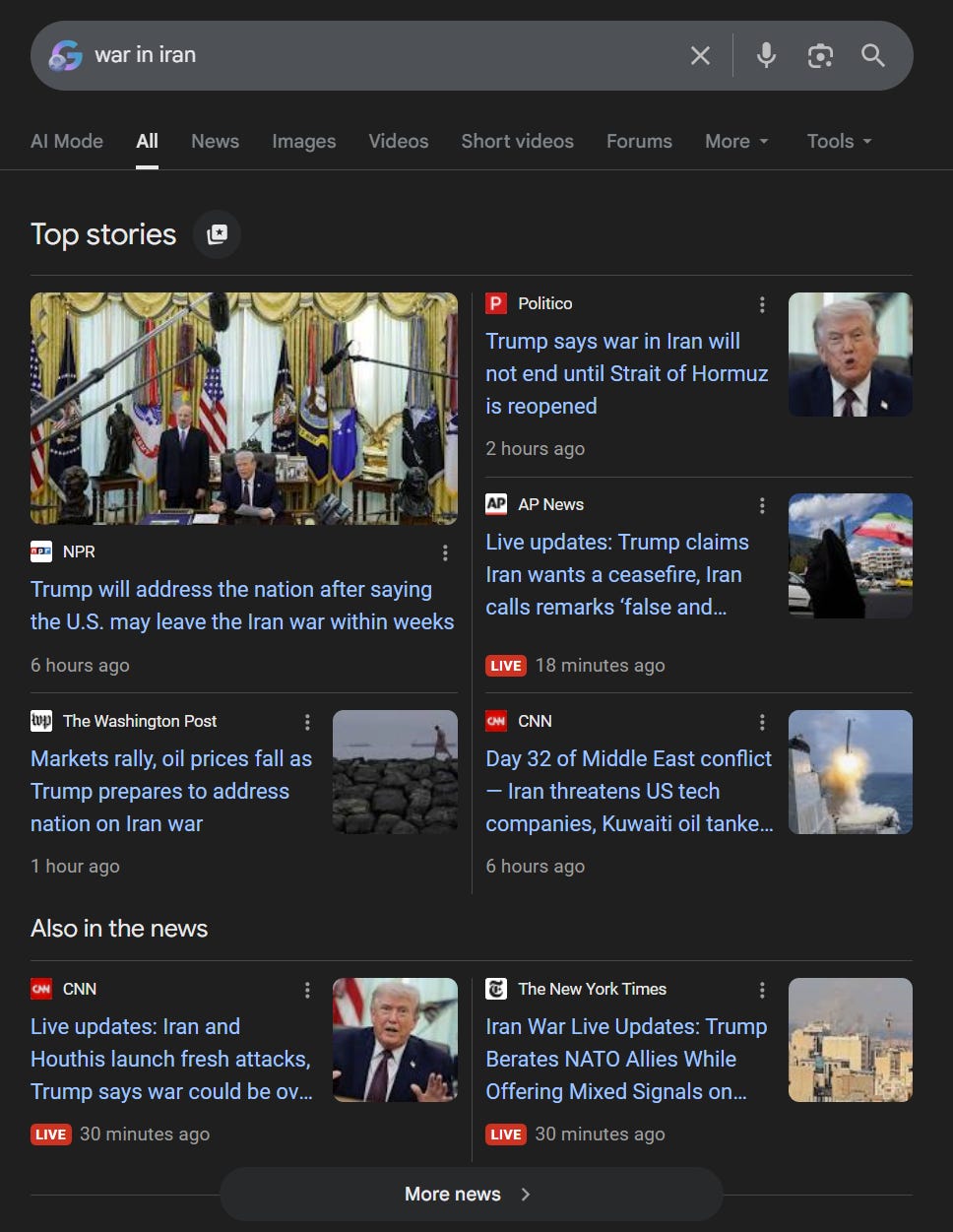
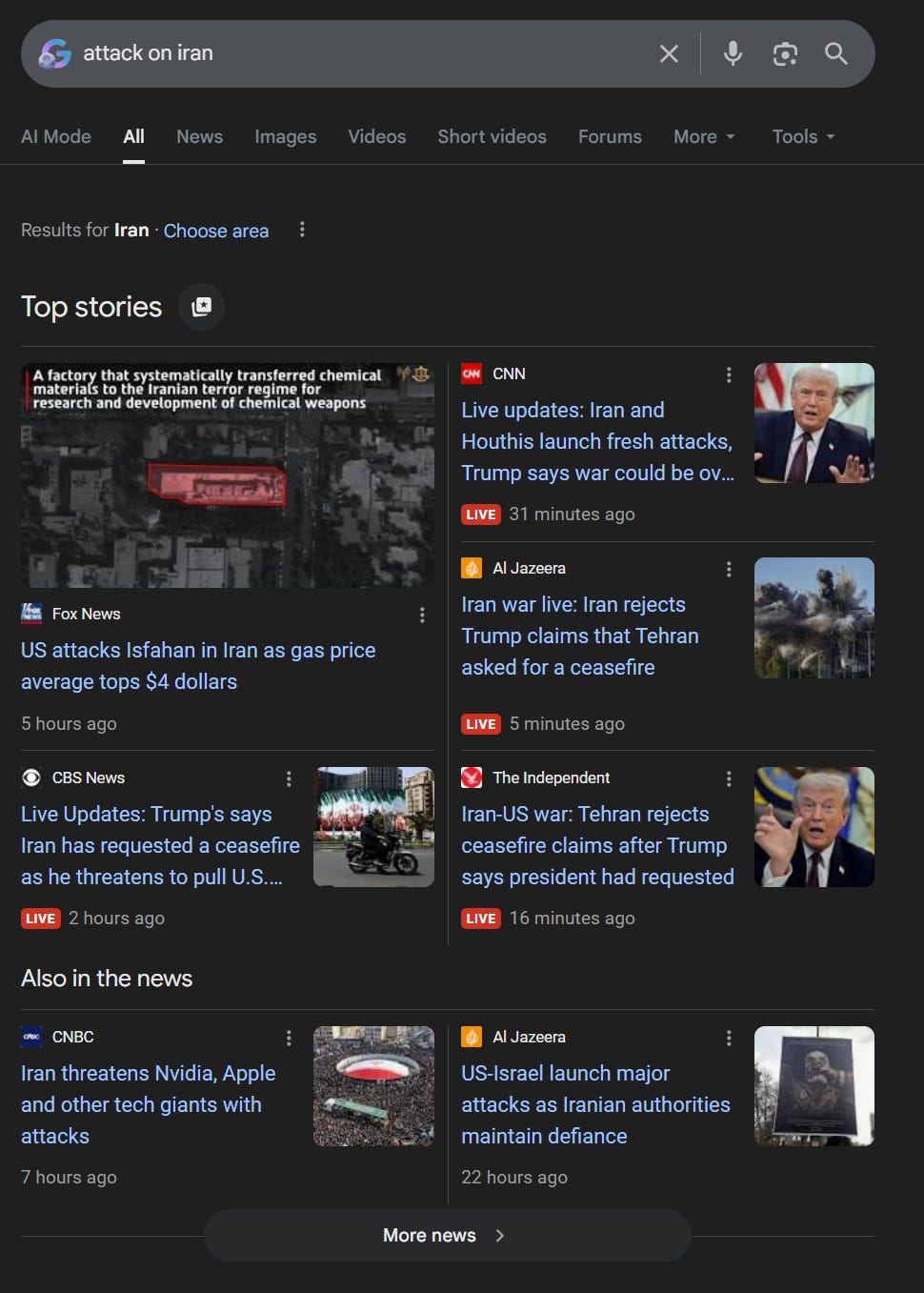
Both searches present credible news sources but there is no overlap between both images.
The first search talks more about what Trump is saying and the impact of Iran’s attacks on markets and the United States. This indicates that these news sources are from a Western point of view and are imbued with relevant prejudice.
The second search reveals more about Iran’s actions (such as rejecting the ceasefire) and US attacks which shows how the news operates from a completely different point of view by looking at Iran’s actions and responses.
The key point is that AI is not inventing these framings from nothing. It is sampling from a landscape of already‑framed human texts. When a model reacts differently to “war in Iran” than to “attack on Iran,” it is echoing how journalists, politicians, and commentators have historically used those phrases. Change the diction and you change which slice of that landscape becomes most probable. The bias does not live only in the machine; it lives in the archive the machine has been trained on.
More Examples of Loaded Diction
You can see similar dynamics across other domains:
“Illegal immigrant” versus “undocumented immigrant” shifts attention from a person’s legal status to their lack of paperwork, modulating blame and empathy.
“Collateral damage” versus “civilian harm” softens responsibility in one case and foregrounds suffering in the other.
“Data collection” versus “data surveillance” names the same technical process but very different social meanings.
In each case, an AI system will respond by drawing on different clusters of sources, arguments, and narratives, not because it has a political ideology in the human sense, but because its training data uses each phrase in different rhetorical ecosystems. When you ask for a summary, explanation, or evaluation using one term instead of another, you are quietly voting for which ecosystem the model should treat as relevant.
What This Means for Using AI
If wording is never neutral, then prompting is never neutral either. Asking, “Explain why global warming is a hoax” and “Explain the scientific consensus on climate change” does not just ask for different content; it constrains the model to two very different regions of its learned space. Likewise, questions framed around “regulations” versus “protections,” “riots” versus “protests,” or “welfare” versus “social support” will tend to produce answers that mirror the argumentative patterns associated with those terms.
This does not mean that careful prompting magically removes bias or guarantees truth. It does mean that we should treat our interaction with AI as some sort of co‑authorship. The model brings its training data and architecture; we bring our assumptions, word choices, and frames.
Conclusion
Language models don’t think in the way we do, but they do inherit and reproduce our habits of speech. Their “decisions” are statistical, yet those statistics are saturated with human politics, culture, and power. If we want AI systems that inform rather than mislead, we have to pay attention not only to how they are trained and governed, but also to the words we feed them. Diction is not an afterthought; it is part of the system. No two words are the same, and in an age of generative AI, that difference matters more than ever.
Pertinent piece. Completely agree that models inherit and reproduce our habits. They are trained on our data after all. Would also be very interesting to see if there is a way to quantify the correlation between the tone/diction in input and output.